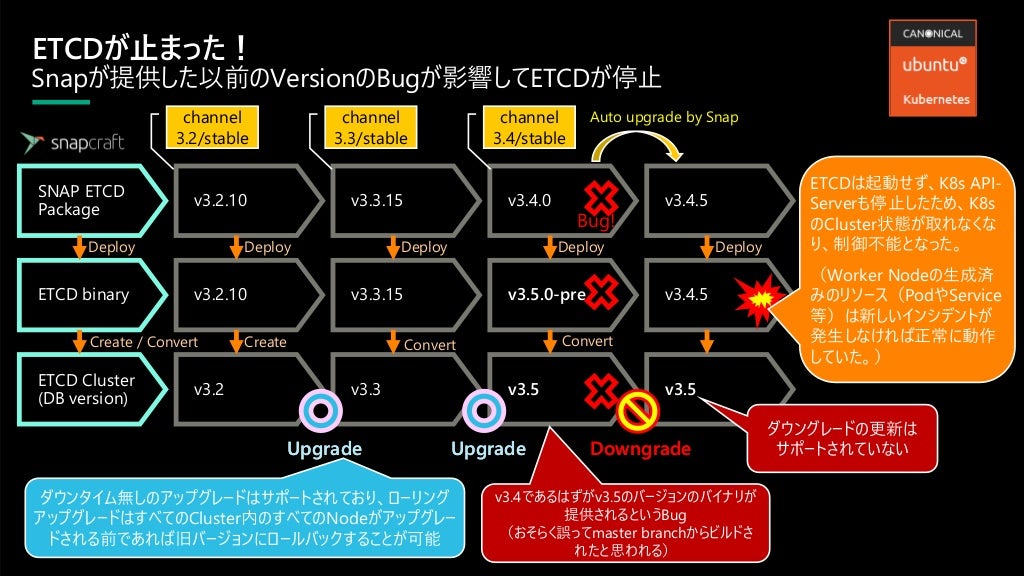
ETCDではdb保護のためUpgradeはサポート(世代に依る)しているが、Downgradeは対応していない。(少なくとも現状のv3.4.x以前のVersionでは)
このため一旦新しいVersionを試した後、旧Versionに戻したいと思っても、起動時に以下のClusterとのVersionの整合性とれない旨のエラーとなり起動しない。
cluster cannot be downgraded (current version: 3.4.5 is lower than determined cluster version: 3.5).
(この辺の処理でガードを掛けている。)
ETCDは新しいVersionのBinaryで起動すると自動的にClusterを新しいVersionへ移行する。(参考:Upgrade procedure)
すべてのNodeにおいて新しいVersionのBinaryで起動するまでは切り戻しは可能であるが、すべてのNodeが新しいVersionで起動するとそのClusterのVersionをもとに戻すことができなくなる。
本番環境では考えられないが、もしシングルNode構成下で(Snapshotも取らずに)早まってBuggyな新しいVersionのBinaryを動かしてしまうと、一発でこの事象に陥る。
本稿はCDKのCharmed K8s環境で構築したシングル構成時におけるDowngradeの方法を示す。(冗長構成下においては一旦シングルNode構成にしてから実施する必要があるだろう。)
ただしDowngradeした後の状態にKVSが正しく機能しているかはサポート外であるため、それぞれの環境で確認する必要がある。
Master Nodeのバックアップ(VMイメージのcloneやsnapshot等)を取得する。
SystemdによりRespawnを繰り返しているはずなので、これを停止する。
$ sudo systemctl stop snap.etcd.etcd.service
手順の流れとしてはbootstrap起動することで新しいClusterを構成した状態を作り、そこにDBファイルを戻す。
snapとwal(Write-Ahead Logging)が格納されているmemberディレクトリをrenameする。
$ sudo mv /var/snap/etcd/current/member /var/snap/etcd/current/member_BK
ETCDはClusterが存在していない初期状態で起動されるとCluster環境を構築する。
設定のinitial-cluster-stateを変更してこのCluster初期起動状態を変更する。
$ sudo sed -i 's/^\(initial-cluster-state: \)existing/\1new/' /var/snap/etcd/common/etcd.conf.yml
ETCDをbootstrap起動することによりmemberディレクトリ配下が生成される。
$ sudo systemctl start snap.etcd.etcd.service
正常に起動しているかを確認する。
以下はsystemdによりrespawnされていないかsystemctl statusによりActiveしてから十分な時間(30秒程度以上)が経過していることを見ている。
$ sudo systemctl status snap.etcd.etcd.service| grep Active
Active: active (running) since Thu 2020-05-14 21:24:13 UTC; 14min ago
snapおよびwalディレクトリが生成されていることを確認する。
$ sudo ls -al /var/snap/etcd/current/member
ETCDを停止する。
$ sudo systemctl stop snap.etcd.etcd.service
退避しておいたsnapからDBファイルを戻した状態でETCDを起動する。
$ sudo cp /var/snap/etcd/current/member_BK/snap/db /var/snap/etcd/current/member/snap/db
$ sudo systemctl start snap.etcd.etcd.service
設定のinitial-cluster-stateを変更してCluster構成済みの状態で起動するようにする。
$ sudo sed -i 's/^\(initial-cluster-state: \)new/\1existing/' /var/snap/etcd/common/etcd.conf.yml
$ sudo systemctl restart snap.etcd.etcd.service
正常に起動しているかを確認する。
以下はsystemdによりrespawnされていないかsystemctl statusによりActiveしてから十分な時間(30秒程度以上)が経過していることを見ている。
$ sudo systemctl status snap.etcd.etcd.service| grep Active
Active: active (running) since Thu 2020-05-14 21:50:41 UTC; 31s ago
この状態でkube-apiserverが動作するはずなので、kubectlコマンド等で正常性を確認する。
$ kubectl get node
NAME STATUS ROLES AGE VERSION
juju-5ddd4a-1 Ready <none> 21d v1.18.2
juju-5ddd4a-2 Ready <none> 21d v1.18.2
juju-5ddd4a-4 Ready <none> 21d v1.18.2
上述の手順後を行った後、Readは出来るものののWriteが出来ない状況(kubectlの場合delete等がT.O.となる状況)に陥った場合、Snapshotを生成してRestoreすることで復旧する。
正常にWriteが出来れば以下のようにctdctl putが成功する。
$ export ETCDCTL_API=3
$ etcdctl --endpoints=http://127.0.0.1:4001 put /TEST/date "$(date)"
OK
$ etcdctl --endpoints=http://127.0.0.1:4001 get /TEST/date
/TEST/date
Fri May 15 22:46:10 UTC 2020
$ etcdctl --endpoints=http://127.0.0.1:4001 del /TEST/date
1
Readだけが出来る状態であれば起動中のETCDからSnapshotファイルを生成し新たなdata-dirを生成(restore)する。
$ mdkir etcd-restore ; cd etcd-restore
$ etcdctl --endpoints=http://127.0.0.1:4001 snapshot save etcd-snap.dat
$ URLS=$(grep ^initial-advertise-peer-urls /var/snap/etcd/common/etcd.conf.yml | cut -d\ -f2)
$ etcdctl snapshot restore etcd-snap.dat --data-dir=data-dir --initial-advertise-peer-urls="${URLS}" --initial-cluster="default=${URLS}"
dbファイルからでもHashチェックをスキップすることで新たなdata-dirを生成(restore)することが出来る。
$ mdkir etcd-restore-from-db ; cd etcd-restore-from-db
$ sudo cp /var/snap/etcd/current/member_BK/snap/db ./
$ URLS=$(grep ^initial-advertise-peer-urls /var/snap/etcd/common/etcd.conf.yml | cut -d\ -f2)
$ etcdctl snapshot restore db --data-dir=data-dir --initial-advertise-peer-urls="${URLS}" --initial-cluster="default=${URLS}" --skip-hash-check=true
生成したdata-dirを適用する。
$ sudo systemctl stop snap.etcd.etcd.service
$ sudo rm -rf /var/snap/etcd/current/member
$ sudo cp -a data-dir/member /var/snap/etcd/current/
$ sudo sed -i 's/^\(initial-cluster-state: \)existing/\1new/' /var/snap/etcd/common/etcd.conf.yml
$ sudo systemctl start snap.etcd.etcd.service
$ sudo sed -i 's/^\(initial-cluster-state: \)new/\1existing/' /var/snap/etcd/common/etcd.conf.yml
ETCDが暫くの間存在していない状態であったため、この間に発生しているWorker Node側の状態変化についての追従が出来ていない。
復旧後、一定時間経過しても状態不一致と思われる挙動が発生した場合は、Worker Nodeの落とし上げを実施する。(kubelet, kube-proxyだけの再起動では復旧しないケースがある模様。)